Quebrando CAPTCHA com OpenCV e Python
Olá,
estou ressuscitando meu domínio aproveitando com um antigo post meu publicado no blog da empresa atualizado. Neste post eu mostro uma introdução a OpenCV usando Python fazendo uma brincadeira com um CAPTCHA real, tentando quebra-lo.
Para quem não sabe CAPTCHA, acrônimo de “Completely Automated Public Turing test to tell Computers and Humans Apart” é algum tipo de teste que tenta diferenciar um computador de um humano e seu objetivo mais comum é o de impedir ferramentas automatizadas de realizar alguma tarefa.
Comumente, um CAPTCHA na WEB é uma imagem contendo letras e números, obrigando o usuário a digitar os caracteres contidos nela para acessar determinado recurso. Se você já se cadastrou em algum webmail ou então preencheu algum formulário, já deve ter se deparado com um CAPTCHA e resolvido ele. Humanos são fantásticos em resolver esse tipo de teste, computadores, por outro lado, sofrem quando encontram um CAPTCHA.
O CAPTCHA que escolhi para isso é simples, com 4 letras, todas com a mesma fonte e alguma variação de rotação. Além disso, algumas linhas recortam a imagem, dificultando a segmentação.

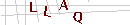

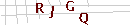
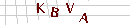

Acima alguns exemplos do CAPTCHA a ser quebrado. É possível dividir o problema em três partes:
Primeiro, é preciso segmentar as letras. O que significa isso? Significa separar as letras umas das outras. Se todas as letras usassem a mesma cor, seria uma tarefa trivial, afinal bastava escolher os pixels que tivessem aquela cor e ignorar o resto. Infelizmente a cor muda a cada CAPTCHA.
Mas existe um padrão. As letras nas imagens sempre tem a cor mais escura. Esse padrão vai ajudar na segmentação das letras. Mas, como diabos, calcula-se a cor mais escura?
Lembra-se do padrão RGB? Red, Green, Blue? Essas imagens estão nesse padrão, usando um byte para a cor vermelha (Red), um para a cor verde (Green) e um para a cor azul (Blue) para cada pixel. Quanto menor o valor de cada byte, menor a intensidade da cor, e menor a influência que ela tem na cor final do pixel e vice-versa.
Usando essa definição dá para dizer que uma cor é mais escura que a outra quando a intensidade dela é menor que a da outra, ou seja, que a soma das cores RGB de uma é menor que a soma da outra. Vamos ver algum código:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# importa a biblioteca do opencv
import cv2
# carrega a imagem colorida e transforma ela em uma matriz do numpy
image = cv2.imread('a.png')
# calcula o pixel com menor intensidade
# inicia a cor com o maior valor possivel
color = 255 * 3
# pega as dimensoes da imagem
(rows, cols, depth) = image.shape
# varre todos os pixels
for row in range(rows):
for col in range(cols):
# acessa um pixel da imagem
pixel = image[row][col]
(r, g, b) = pixel.tolist()
if color > (r + g + b):
color = r + g + b
O código acima é simples, mas introduz questões básicas do OpenCV. A primeira delas é a linha 5, como carregar uma imagem para a memória. A segunda é como pegar o tamanho da imagem (linha 11). É interessante perceber que, ao contrário de uma imagem, que tem altura e largura, o OpenCV trabalha com o conceito de Matriz matemática, que tem linhas e colunas. E por último, como acessar um elemento da matriz (linha 18). Como a imagem foi carregada como colorida, cada pixel tem 3 componentes (r, g e b). Se ela tivesse sido carregado como escala de cinza, cada pixel teria apenas um componente, o tom de cinza.
Agora que temos a cor das letras, podemos partir para o próximo passo, a binarização da imagem. Binarização de uma imagem é o processo de transformar uma imagem que tem varias cores em uma imagem que tem apenas duas, preto e branco. Vamos pintar de preto todos os pixels que forem da cor das letras e pintar de branco todos os outros pixels, assim removeremos as linhas e poderemos segmentar cada letra.
1
2
3
4
5
6
7
8
9
10
11
12
for row in range(rows):
for col in range(cols):
pixel = image[row][col]
(r, g, b) = pixel.tolist()
c = (r + g + b)
# pinta de branco o que nao for letra
if c != color:
image[row][col] = (255, 255, 255)
# pinta de preto o que for letra
else:
image[row][col] = (0, 0, 0)
No código anterior tínhamos mostrado como acessar um pixel da imagem. Agora, nas linhas 9 e 12, mostramos como escrever mudar um pixel da imagem. Muito simples, não? O resultado final é o seguinte:

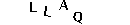
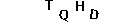
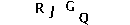
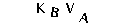
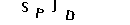
O último passo para segmentar as letras é o recorte. Precisamos calcular quais coordenadas delimitam uma letra, com essas coordenadas definiremos um quadrado em volta da letra, esse quadrado é conhecido pelo termo Bounding Box.
O cálculo das coordenadas do Bounding Box pode ser feito da seguinte maneira. Acha-se um pixel que contenha a cor da letra. A partir desse pixel, se pega a coordenada dele, e vê se os vizinhos tem um pixel da cor da letra também. Esse método é chamado recursivamente para esses vizinhos, retornando as coordenadas deles. Com essas coordenadas, achamos o menor e maior x e o menor e maior y, eles definem o bounding box dessa letra.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def recursive_bounding(image, row, col, letter_color):
min_x = col
min_y = row
max_x = col
max_y = row
(rows, cols, depth) = image.shape
for r in range( max(0, row - 1), min(row + 2, rows)):
for c in range(max(0, col - 1), min(col + 2, cols)):
if r == row and c == col:
continue
(r1, g1, b1) = image[r][c]
t = (r1 + g1 + b1)
# vizinho nao pertence a letra, ignora ele
if t != letter_color:
continue
# apaga esse pixel
# nao salvamos ele como branco pq precisaremos dele
# no proximo processamento
image[r][c] = (20, 20, 20)
points = recursive_bounding(image, r, c, letter_color)
(min_x1, max_x1, min_y1, max_y1) = points;
min_x = min(min_x, min_x1, c)
max_x = max(max_x, max_x1, c)
min_y = min(min_y, min_y1, r)
max_y = max(max_y, max_y1, r)
return (min_x, max_x, min_y, max_y)
Agora temos a bounding box de uma letra, precisamos encontrar todos bounding boxes para todas as letras. Para isso, varreremos a imagem em busca de pixels com a cor da letra, encontrando, chamaremos a recursive_bounding, que dará conta do resto.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
boxes = []
letter_color = 0
for row in range(rows):
for col in range(cols):
pixel = image[row][col]
(r, g, b) = pixel.tolist();
t = (r + g + b)
# nao eh letra, ignora o pixel
if t != letter_color:
continue
# calcula a bounding box dessa letra
box = recursive_bounding(image, row, col, letter_color)
# salva o bounding box numa lista de boxes
boxes.append(box)
boxes.sort()
Nenhuma novidade aqui, percorremos todos os pixels da imagem procurando por um pixel que corresponda a uma letra e chamamos a recursive_bounding para calcular a bounding box dela. No final desse código teremos 4 boxes com as coordenadas de cada letra. Ordenamos a lista para que a letra mais a esquerda fique em primeiro, a segunda letra mais a esquerda fique em segundo, e assim por diante.
O próximo passo é recortar essas letras e comparar com uma base de letras. Podemos comparar com uma base fixa apenas porque as letras não variam quanto ao tamanho, fonte e rotação. Caso variassem, teríamos que ter outra estratégia de análise.
1
2
3
4
5
6
7
letters = []
for box in boxes:
(col0, col1, row0, row1) = box
letter = image[row0:row1 + 1, col0:col1 + 1]
letters.append(letter)
Na linha 6, mostramos como recortar um retângulo da imagem. Como a imagem é um vetor numpy, o recorte funciona como funcionaria para um vetor nativo do python. A variável letter conterá a imagem da letra final.
A base de comparação que usaremos será um diretório com todas as letras, previamente classificadas por um humano (eu). Para classificar as letras, fiz um recorte com dezenas de imagens e salvei em um diretório. Depois as nomeei com letra.png (por ex. a.png, b.png, etc.). Agora, tudo o que precisamos é de um método que lê esse diretório, carregando os templates em uma lista, para serem comparados com as letras recortadas da imagem.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import os
import glob
import collections
def load_templates():
# filtra os arquivos .png
files = glob.glob('templates/*.png')
# dicionario com as imagens
# chave = letra
# valor = lista de imagem
templates = collections.defaultdict(list)
for file in files:
f = os.path.basename(file)
# o primeiro caracter do nome do arquivo eh a letra
# correspondente
letter = f[0]
# carrega a imagem
img = cv2.imread(file)
# muda a imagem pra tons de cinza
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# binariza a imagem
(_, img) = cv2.threshold(img, 245, 255, cv2.THRESH_BINARY)
# uma letra pode ter varios templates
templates[letter].append(img)
return templates
A maior parte do método é de comandos nativos do python. Ler um diretório, filtrar arquivos, pegar o nome do arquivo, etc. As novidades quanto ao OpenCV estão nas linhas 25 e 28.
A linha 25 pega uma imagem em RGB e transforma ela em escala de cinza. Já a linha 28 binariza uma imagem usando o método threshold da OpenCV. A idéia dele é transformar todos os pixels que estão abaixo de um determinado número (threshold) em preto e os que tiverem acima desse número em branco. Esse limiar é o segundo parâmetro do método. Com isso não precisamos varrer a imagem inteira trocando os pixels, que no caso de uma imagem muito grande (3000 x 2000, por ex.), representa um ganho gigantesco de desempenho.
Agora que temos os templates das letras e as letras que queremos reconhecer, basta compararmos pixel a pixel e a que mais tiver pixels parecidos é a nossa letra. Vamos ao método final:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
def break_captcha(letters, templates):
captcha = ''
unrec = 0
for letter in letters:
(rows, cols, depth) = letters.shape
best_error = rows * cols
best_letter = ''
# copia a imagem, transformando de RGB para tons de cinza
gray = cv2.cvtColor(letter, cv2.COLOR_RGB2GRAY)
# binariza a imagem
(_, blackwhite) = cv2.threshold(gray, 240, 255, cv2.THRESH_BINARY);
for letter in templates:
for template in templates[letter]:
# se a imagem for de tamanho diferente do template
# ignora o template
if template.shape != blackwhite.shape:
continue
# calculamos a diferenca entre as 2 imagens binarias
xor = template ^ blackwhite
errors = xor.sum()
if errors < best_error:
best_error = errors
best_letter = letter
# match perfeito
if errors == 0:
break;
# match perfeito
if best_match == 0:
break;
# nao casou exatamente com nenhuma letra
# provavelmente eh uma nova letra
if best_error != 0:
cv.SaveImage("image_%d.png" % (unrec), gray)
unrec = unrec + 1
captcha = captcha + best_letter
return captcha
Na linha 12, convertemos a imagem de um tipo para o outro, nesse caso de RGB para escala de cinza (RGB2GRAY). E, por fim, na linha 15 binarizamos a imagem, fazendo o threshold dela.
Depois comparamos cada letra apenas com os templates que tem exatamente o mesmo tamanho que a letra. Em vez de fazermos uma comparação byte a byte, fazemos um xor entre os arrays numpy , que aplica a operação de XOR em todos os elementos das duas matrizes, populando uma terceira matriz onde os indices que casaram recebem 0 e os que não casaram recebem 1.
Por fim, somamos todos os valores da matriz resultando para contar quantos erros tivemos. O template que tiver 0 posições erradas é a letra certa. Se nenhuma tiver 0 erros, então salvamos a letra para análise posterior, assim conseguimos resolver o CAPTCHA.
Esse artigo eu escrevi em maio de 2009 e, ainda hoje, o serviço de onde peguei esse captcha continua ativo. Mas, ao contrário da outra vez, disponibilizei um zip com os arquivos de template treinados e um ipython notebook com o codigo funcionando.